Build Your Own Damn Static Site Generator
The first project I recommend for aspiring software engineers, or any technical profession really, is creating a personal Website. It's easy to do, serves a pragmatic purpose, gives you something interesting to write about, it's as difficult as you want it to be, serving static sites is low-risk, and, in my opinion, if you want to get hired nowadays, it's essential to prove that you're a real human being with critical thinking skills.
Generative AI changed the job market in a surprising number of ways. Most people understand that developers being able to do more with less, along with the post-COVID tech bust, was going to result in some industry belt tightening, but what they miss is that AI makes it incredibly hard to filter candidates. An applicant can seem pretty confident, have the certifications and education to back it up, ace the coding test and the take-home, and even have some public projects on Github, however, it's not too hard to give a false impression in an interview that lasts less then an hour, certs aren't so hard to acquire, rolling small applications with a believable commit history in an AI editor like Cursor is easy, and now there's even AI tools that create invisible windows with solutions in live interviews[1], so not even the Leetcode filter is safe!
You might reccomend that companies be more thorough in their interviewing process, with solutions such as:
Have the candidate spend more time with the people they're going to be working with
Make the candidate write an essay on an area of their expertise and run that through an AI detection filter
Only hire people who've been vouched for by a professional network[2]
Filter anyone without so many years of experience or extensive open-source contributions
The problem is that most of these efforts require more of an engineer's time, which is expensive, drastically reduce the applicant pool, especially for junior positions, or makes the company non-competitive in terms of hiring practices. That last point might sound weird, but I know quite a few competent technological people who straight-up refuse interviews that require any sort of "homework" in the process since they see it as a waste of time. But then again, most of those people also had public Github projects prior to the rise of generative AI.
This is why I think it's paramount that the modern-day technical professional have a personal site where they blog about their projects and fields of interest, it saves everyone a lot of time by showing you aren't just propped up by a robot and actually care about these things. Not that there aren't a myriad of other benefits like making the Internet a more interesting place, developing writing skills, and reflecting on different subjects, but for junior engineers, the bait of "this'll help you get a job" is pretty effective.
If you'd like to just see how this site was built, the source is available on my github, otherwise read-on for an in-depth explanation.
The Game Plan
There's a lot of easy options for setting up personal Websites nowadays, but I'm a bit of a Scrooge when it comes to blogging platforms like Medium and site-builders like Wordpress. Virtual Private Servers(VPS) and Domain Name Registration are both pretty cheap nowadays, there's many tools for generating HTML from Markup documents like Hugo or Pandoc, and if you want things to look nice and cooperate you can just Google for a nice Stylesheet or ask the AI to make one for you.
To make things a little more difficult for myself, I ended up rolling my own static-site generator in Clojure in order to take documents from my Org-Roam database tagged with PYD [3] , parse them myself, and turn them into this Website. I took this approach for a few reasons:
I can keep all my writing in Org-Roam
Most Org to HTML converters don't satisfy me
I might want to implement more complex features in the future, so I want a granular amount of control over document generation
Parsing rich text is an interesting problem most people can understand, which makes it easy to write about
Outside of that, I just rented a VPS, installed Nginx and configured it to serve the site as a file server, opened a few ports, bought a domain name[4] and pointed it at the rented server, and finally I run rsync to push the generated files up to the VPS.
What's a Static-Site Generator?
Before we dive into the specifics of parsing Org to HTML, lets talk about the problem that's actually been solved. Static-Site Generators(SSG) are programs that take in some files, such as blogs written in Markdown, images, videos, and .csv tables and spit out a folder of .html files and other assets that you can serve over a file server as a Website.
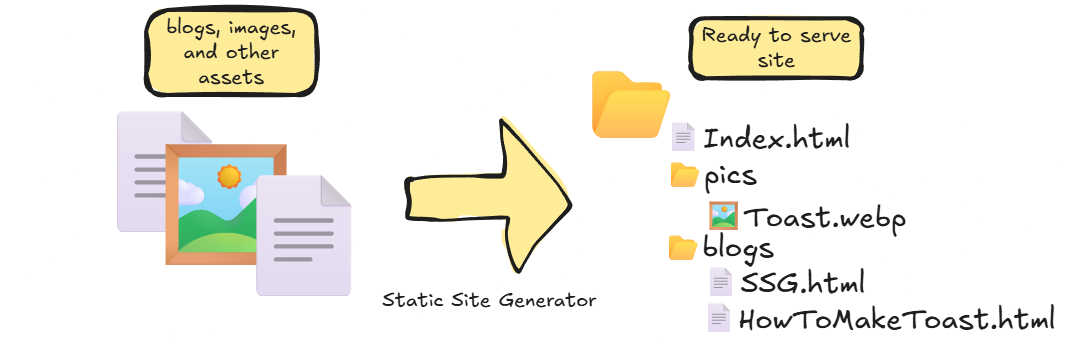
This is ideal in cases where you want to present content that changes infrequently over the web such as:
Programming documentation generated from code comments
Data dictionaries created from schema repositories
School, Church, and Business bulletin boards for basic contact information and events[5]
Blogs(like the one you're currently reading)
Simple analytic and alert dashboards
If you're also willing to add smidgen of JavaScript you can implement things like search bars and code highlighting for a little dynamic behavior. I think so long as you aren't relying on a server or using a JS framework that redraws the page you can still call things static.
Parsing Org File Metadata
The first challenge is to scan through all of the files in my Org-roam database and parse the document metadata, which lives at the top of every file and looks something like this:
:PROPERTIES:
:ID: 16c78923-1a39-48ab-be9e-5a9521b30ace
:END:
#+title: Build Your Own Damn Static Site Generator
#+filetags: :PYD:
#+slug: I built this site with a Static-site generator I wrote myself in Clojure. It's not so hard to sling some markup into html. Although it'd probably be faster if I just used Hugo.
#+pubdate: Wed, 16 Jul 2025 17:55:25 -0400
\newline(not literally '\newline', but the newline character '\n')
This is mostly self-evident except for two points:
:ID:is the Org-roam unique id that doesn't change and is used internally to link documents togetherslugandpubdateare both properties I've defined myself
With all that in mind, we can retrieve the metadata by:
Opening the document, reading until we hit a newline character
\nFor each line, check against a regex expression, and extract the value if it matches the property we're looking for
(defn get-org-file-metadata
"Given a path to an org file, parse it's properties into a map"
[org-file-path]
(let [f (io/file org-file-path)]
(assert (.exists f) (str "org file doesn't exist " f))
(with-open
[r (io/reader f :encoding "ISO-8859-1")]
;; Read until we see the new line character
(let [top-block (take-while #(not (= % \newline)) (line-seq r))]
;; A small function to find the expected line in the block, given a regex pattern
(letfn [(get-line-value [s pattern]
(->> s
(map #(re-find pattern %))
(filter #(not (nil? %)))
first
second))]
;; Various ways of handling the property value
{
;; take the value literally
:roam-uid (get-line-value top-block #":ID:\ +(.*)")
:title (get-line-value top-block #"\#\+title:\ +(.*)")
:slug (get-line-value top-block #"\#\+slug:\ +(.*)")
;; Split the tags into a list
:tags (let [t (get-line-value top-block #"\#\+filetags:\ +(.*)")]
(if (nil? t)
`()
(rest (str/split t #":"))))
;; parse the publish date into Day-Month-Year
:pubDate (let [d (get-line-value top-block #"\#\+pubdate:\ +(.*)")]
(if (nil? d)
""
(rfc->dmy d)))
;; Just pass the path along
:path org-file-path})))))
Using Hiccup for HTML Conversion
To avoid spending too much time trying mangle XML-like strings, I've used the Hiccup library as an intermediary step between Org markup and HTML:
(require '[hiccup2.core :as h])
;; HTML elements are represented by vectors
;; The first element is a keyword signfying the element type
(str (h/html [:p "foo"]))
;;"<p>foo</p>"
;; The second element can be a map describing element properties
(str (h/html [:img {:src "/images/foo.png" }]))
;; "<img src=\"/images/foo.png\" />"
;; There's nothing special about the vector we pass to the the Hiccup function
;; So we can manipulate the list prior as we please
(str (h/html (vec (concat [:ul]
(reduce
(fn [accm n] (conj accm [:li [:p n]]))
[] '("one" "two" "three" ))))))
;; <ul><li><p>one</p></li><li><p>two</p></li><li><p>three</p></li></ul>
Parsing the Body of the Org File
While Org properties at the top of a file can be easily parsed line-by-line, transforming Org elements into HTML is a fair bit trickier:
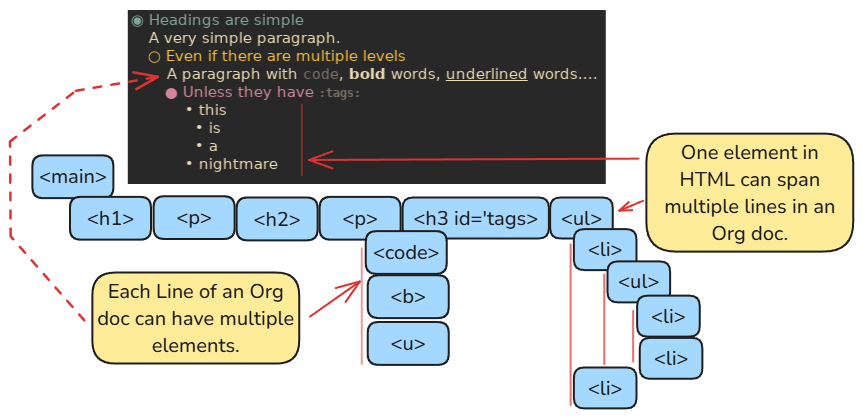
You have "block" elements like lists and code blocks which can span a couple lines, but result in one HTML element being created(oftentimes with multiple children)
Formatting elements, such as bolded words, that causes a single line in Org to create an HTML element with many children.
To handle this, I've parsed the body in two steps, reducing the lines into block elements, parsing single line elements as I go, and then handling block elements piece-by-piece.
Reducing Multi-Line Elements Into a Single Element
Normally when we reduce in clojure we try to not give too much consideration to the accumulator:
(reduce (fn [accm n] (+ accm n)) `(1 2 3 4 5)) ;; 15
(reduce (fn [accm n] (conj accm n)) `() `(1 2 3 4 5)) ;; (5 4 3 2 1)
But when grouping sequential items, like lines of text, some "look back" becomes necessary, such as when we're parsing code blocks that begin with #+begin_src lines and end with #+end_src lines, with everything in between being formatted as code.
For this, I begin all code blocks like so: [:pre :open [:code {:class lang}]] [6] with the :open element indicating that an element has yet to be closed and any lines after which should be added to it:
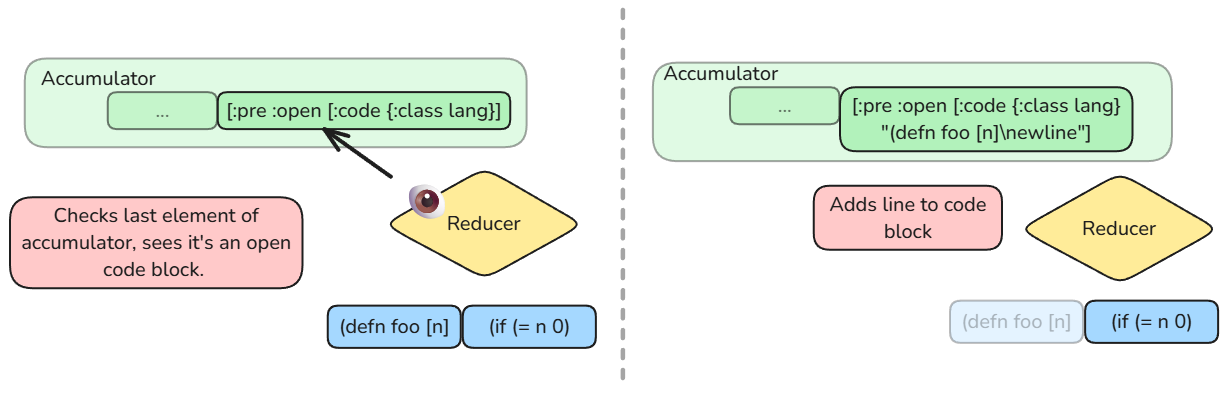
Once the reducer sees #+end_src the :open element is removed and the grouping continues as normal. The same logic is used for Quote blocks as well, which follow a similar pattern of #+begin_quote and #+end_quote. Unordered lists do not use this logic, since all list items are prefixed with a dash, making it easy to infer when a list starts and ends.
Parsing Headings
Headings in Org are denoted by a number of asterisks characters, so * denotes a top-level heading, ** denotes a second-level heading, and so on. Within HTML, headings are denoted as different element types such as <h1>, <h2>, and so on. This makes the conversion pretty simple:
;; Construct the keyword based on the number of asterisks
;; ** -> :h2, *** -> :h3, and so on
[(keyword (str "h" (count first-token)))
;; retrieve the text of the elemnt
(str/trim (apply str (drop-while #(= \* %) line)))]
Parsing Images and Introducing Side-Effects
Since displaying images requires that the file be present on the server, we need to make sure to copy the image from the Org-Roam database to the /target/images/ directory and ensure the src property on the :img element points to it. Files embedded in Org are formatted like: [[file:FILENAME_PATH]] and for the purpose of my parser, I just consider all files to be images.
(let [image-file
(io/file
(str/replace-first
(second (re-matches #"\[\[file:(.*)\]\]" line))
#"~" (System/getProperty "user.home")))
new-filepath (str "/images/" (.getName image-file))]
(FileUtils/copyFileToDirectory
image-file
(io/file "target/images/"))
[:img {:src new-filepath}])
Parsing Lists(Trees in Plain Sight)
Unlike code or quote blocks, lists have the potential to be nested, and so we have to consider that each sub-element could be the beginning of a new list. An intuitive way to think about it is that reading the list top-to-bottom is an in-order traversal of some tree[7].
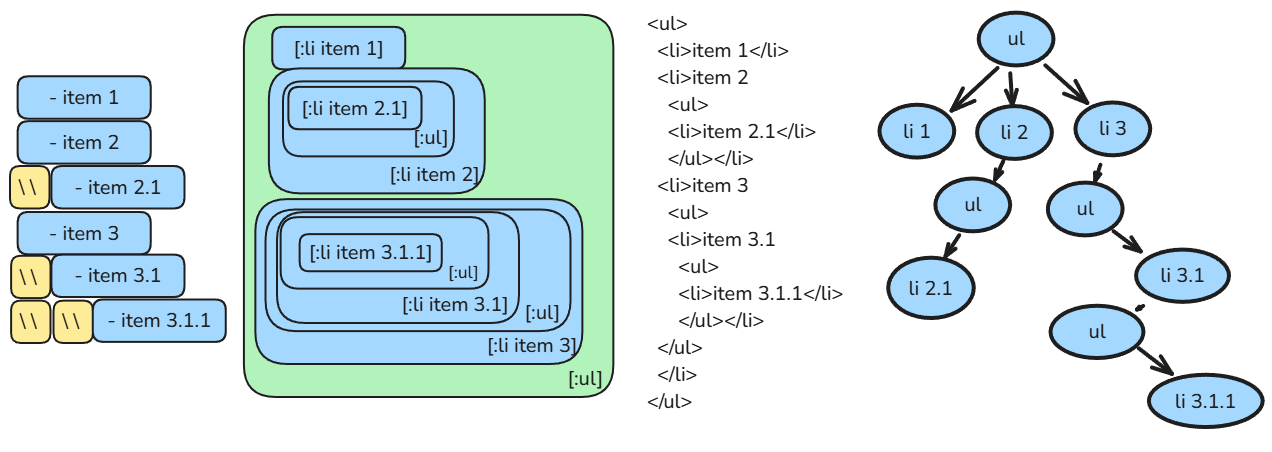
As with most cases concerning trees, the solution here is to build the data structure by adding elements, recursively descending until we're at the correct level to add the element, a procedure we could describe as[8] :
Are we at the right indentation level?
Yes
Add the element to the current list
No
Is the Last element a list element(
:ul)?Yes
Descend into the list, decrement the indentation level, go back to the first step
No
Create a new sub-list with our element as the sole element
(defn add-element-to-list-in-order
"Adds an item to the end of a ul element at the specified level."
([elem line]
(let
[space-prefix (count (take-while #(= \space %) line))]
(assert (= (mod space-prefix 2) 0) (str "Space prefix for " line " Is not even"))
(add-element-to-list-in-order elem [:li (parse-paragraph (str/replace line #"^\ *- " ""))] (/ space-prefix 2))))
([elem li level]
(assert (= (first elem) :ul) (str "Tried to add list item" li "to non-list element: " elem))
(if (= level 0)
;; If we're at the correct indentation level, add the item to the list
(conj elem li)
(let [last-elem (last elem)]
(if (= (first (last last-elem)) :ul)
;; list exists at the indentation level Descend into it
(conj (pop elem) (assoc last-elem 2
(add-element-to-list-in-order (last last-elem) li (dec level))))
;; sub-list does not exist, create it and add the item as the first element
(conj (pop elem) (conj last-elem [:ul li])))))))
You'll notice an assertion I make is that all indentation levels must be two spaces. I don't believe this is required by Org, but it's what my Emacs produces by default and I'd rather be consistent in writing then handle the case gracefully. I will however make that expectation explicit.
Parsing Paragraphs
The most difficult part of the this project, parsing individual paragraphs of text, with formatting and different elements like footnotes and links, is pretty tricky to get right.
My first approach was along the lines of Maximal Munch, where when parsing some construct, you want to consume as much input as possible each step, and so I would try to consume characters in "runs" that would be parsed into elements, either just text, or formatted elements like [:i] for italics, [:b] for bold, and [:a] for links. You can still see evidence of this approach with my handling of bracketed elements:
(let
[run (parse-bracket p-text)
rc (count run)
new-elem (cond
(re-matches #"\[fn:.*\]" run) (parse-footnote run)
(re-matches #"\[\[https:.*\]\]" run) (parse-link run)
(re-matches #"\[\[id:.*\]\[.*\]\]" run) (parse-local-link run))]
(recur
(conj coll new-elem)
(drop rc p-text)
\]
f-char)
However, the issue became that I didn't have the best idea of when a formatting sequence would end. As an example, italic formatted elements are wrapped in the forward-slash character: / so you'd assume they'd end when you see a matching forward slash(nested elements not withstanding), but what about CI/CD? miles/hour? You don't want to stop consuming input at these characters, rather you want to eat until you see the formatting character, followed by a space. But it doesn't have to be a space, it could also be a period, dash, right parentheses, newline....
This is a good time to mention that I didn't look at the official Org documentation or any existing tree-sitters, but if I ever have to do any incremental parsing ever again, I'll probably check for an existing tool or established grammar first.
Lesson learned aside, for formatting sequences, I decided to parse them character-by-character instead in order to better understand what these cases were and account for them. Later I'll probably end up converting this to a less granular iterative process that parses runs of text and then handles those cases appropriately, but for now this is approach is good enough.
The skeleton of parse-paragraph is a recursive loop that primarily parses character-by-character, ceasing when there's no text left to process:
(defn parse-paragraph
[s]
(loop [coll [:p]
p-text s
l-char nil
f-char nil]
(let [[next-char & text-left] p-text
f-chars #{\/ \~ \- \* \_}
b-chars #{\. \, \- \) \space}
prefix-chars #{\. \, \- \( \space}]
(if (empty? p-text)
coll
(cond
;; Handle cases
)))))
Initially this was nested directly within the blog-page function, hence the loop syntax instead of using recursive calls to parse-paragarph with variadic arguments like [s] and [coll p-text l-char f-char] akin to what I did for add-element-to-list-in-order above. I'm unsure which format I like better. Assuming it's purely syntactical sugar, loop, recur makes the recursive operation explicit, while variadic arguments save me a form.
To explain some of the bindings which may not be immediately self-evident:
f-charsare formatting characters within Org, such as~for code-formatted text and/for italic textf-char, if notnil, is the formatting character of the formatted run of text we're inl-charis the last character processedb-charsare "breaking characters" which are used to end a formatting sequence after a matching formatting character is foundprefix-charsare characters that, if followed by a formatting character, begin a formatted bit of text.
Within the cond block, I have a number of complicated cases to check what to do at every character, which can abstractly be described as follows:
Begin a formatted sequence
End a formatted sequence
Add to a formatted sequence
Parse a link(hyperlinks as well as footnotes)
Adding text to a string at the end of
coll~Adding a string to the end of
coll, with the character as the sole element, after we finish creating something like a formatted run or a link, starting a new "normal" string of text
Beginning a Formatted Sequence
(and
(f-chars next-char)
;; The character before a formatting character must be the start of a list or
;;;; It must be at the beginning of the list
(or (prefix-chars l-char) (nil? l-char))
;; Don't start another formatting sequence when we're already in one
(nil? f-char)
;; Don't begin a formatting sequence if there's no text left
text-left
;; Don't begin a formatting sequence if there's no matching ending character
;;;; followed by a breaking character
(re-find (re-pattern
(str \( \\ next-char \$ \|
\\ next-char "\\." \|
\\ next-char \, \|
\\ next-char "\\)" \|
\\ next-char \- \|
\\ next-char \space \))) (apply str text-left)))
(recur
(conj coll [(case next-char \/ :i \~ :code \- :s \* :b \_ :u) ""]) ;;coll
text-left ;; p-text
next-char ;; l-char
next-char) ;;f-char
As explained above, they're a number of edge cases to formatting text. As such, I've heavily annotated the above code to try and give a better understanding of what cases I'm accounting for.
The constructed regular expression might be the most suspect part of this program, and if I wanted to, I could re-write it to be a little less redundant:
(re-pattern
(apply str
(concat `(\()
(interpose "\\|" (map #(str \\ next-char (str %)) f-chars ))
`(\)))))
However, I think this just serves to sort of "hide" what I'm actually doing. That, and the fact that this complexity moves up once I implement a full on maximal munch approach makes me want to leave it as-is.
Ending a Formatted Sequence
(and
f-char
;; The last character we processed was a matching formatting character
(= l-char f-char)
(or
(= next-char \space)
(empty? text-left)
(and
(b-chars next-char)
;; The breaking character is either the last character or is followed
;;;; by another breaking character
(or (empty? text-left) (b-chars (second p-text))))))
(recur
(conj (conj
(pop coll)
(assoc
(last coll) 1
(apply str (butlast (last (last coll)))))) ;;coll
(str next-char))
text-left ;; p-text
next-char ;; l-char
nil) ;; f-char
The first notable part of this case is that I didn't quite nail when a sequence ends. What tipped me off was cases with . such as .dev where a period is a breaking character, it ends a formatting sequence but only if it's followed by a space since this becomes a new sentence. My solution is to just check if there's a second breaking character after the first, which includes spaces, and not end the sequence if there isn't. There's probably an edge case or two here, but this is another 95% solution for me.
The second notable part is the fiddling with the vector in the first argument of the recursive call, where you can see me working around Clojure's immutability. How it essentially works is that:
The last element of
collis removedWe create a new string from that last element, excluding the formatting character we added
Remember this is considering the line character-by-character so this is the step after a formatting character was added
We `assoc` -iate the last element of the last element of coll with our new string
Vectors in clojure can be 'indexed' by numbers. I assume a formatted element will have two members, a keyword and a string of text that'll end up formatted like
[:i "this text is italic"]
That element is
conj-oined to the end of our collection.
I appreciate the immutable nature of Clojure, but I often run into cases like this were I wonder "Am I doing something silly?" the answer to which is typically yes or yes, but however much you want to write a macro to simplify this, you should wait until you find yourself doing the same thing a hundred more times.
Parsing Links
Another nuance introduced by the Org-Roam database is that a link could be to another Website or another Org-roam document, denoted by it's unique id. The forms are:
[[https:LINK][LINK_TEXT]]for hyperlinks[[id:ORG_ROAM_UNIQUE_ID][LINK_TEXT]]for internal Roam links[fn:FOOTNOTE_NUMBER]for footnotes
Local Links
Parsing hyperlinks into anchor elements is simple enough, however, for local Org-Roam links, we need to associate the UID with the expected link in a map that we define in the local environment before we begin parsing blogs:
(def local-links
(map
#(hash-map
:roam-uid (:roam-uid %)
:link (str "/blogs/" (str/replace (:title %) #" " "-")))
blogs-metadata))
Since this is a one-and-done program I simply define local-links with a def in the environment. I had used a dynamic binding at one point to achieve this, but that was erroneous because this value shouldn't change while the program is running.
Once we have this map, we can easily create the anchor element, pointing at where the generated page will be:
(defn parse-local-link
"Parse a string like [[id:some-roam-unique-id][link name]] into a link element"
[s]
(let
[[_ id remark] (re-find #"\[\[id\:(.*)\]\[(.*)\]\]" s)
link (:link (first (filter #(= id (:roam-uid %)) local-links)))]
(assert link (str "tried to link to roam page with remark: \"" remark "\" with id: \"" id "\" with no link entry!"))
[:a {:href link} remark]))
Handling Footnotes
While you might not think of footnotes and their associated superscript as links, they're effectively that as they link two parts of the same text together, so it's useful to provide the user with some way to navigate between them.
(defn parse-footnote
"Parse a string like [fn:n] into a footnote-sub element"
[s]
(let
[n (apply str (take-while #(not= \] %) (drop 4 s)))]
[:a {:class "footnote" :name (str "back_" n) :href (str "#footnote_" n)}
[:sub (str "[" n "]")]]))
The only thing new here is providing a name attribute with the footnote number and creating a document-local href reference to the footnote that will be created at the bottom of the page, e.g. back_2 will link to #footnote_2 and vice-versa.
Of course, we need to create the footnote at the bottom of the page for this to work, which we do with all the line beyond the Footnote header element:
(defn parse-ending-footnote
"Parse a footnote at the end of the file of form \"[fn:n] footnote content\" into a footnote element"
[s]
(let [footnote-number (apply str (take-while #(not= \] %) (drop 4 s)))
footnote-element (assoc (parse-paragraph (drop 1 (drop-while #(not= \] %) s))) 0 :span)]
[:div [:a {:href (str "#back_" footnote-number) :name (str "footnote_" footnote-number)} (str "^" footnote-number)] footnote-element]))
RSS Thread Generation
Really Simple Syndication(RSS) is an easy way to notify readers of your site when you publish something new. All you need to do is provide an XML-like document at some well-known location on your site(I use /feed.xml) and let users know where it is, either with a prominent button or by providing an element in the <head> of your HTML page that will point it out for RSS readers like so: <link href="/feed.xml" rel="alternate" type="application/rss+xml"> . And that's it, now users can subscribe to your site and get notified of updates without having to have any sort of account.
The only rub is that the RSS Specification has a bit of nuance to it and if you're not careful you can mess things up for subscribers with mistakes like:
Changing the address of your RSS feed without "tomb-stoning" your original feed[9]
Mangling the links to the content
Flooding the feed with updates without rolling off old posts, slowing things down for people with RSS readers that don't have strict limits
I hope to mostly avoid these issues by keeping my RSS feed template in source control and limiting the amount of blogs to the last 20:
(defn generate-rss-feed
"Generate an RSS feed from a collection of posts"
[blog-info]
(str "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n"
(h/html
{:mode :xml}
[:rss {:version "2.0"
:xmlns:atom "http://www.w3.org/2005/Atom"
:xmlns:content "http://purl.org/rss/1.0/modules/content/"}
[:channel
[:title "Ryan Ellingson"]
[:description "Personal blog of Ryan Ellingson."]
[:link "https://www.ryanellingson.dev"]
[:atom:link {:href "https://www.ryanellingson.dev/feed.xml"
:rel "self"
:type "application/rss+xml"}]
[:pubDate (-> blog-info first :pubDate)]
[:lastBuildDate (current-rfc822-timestamp)]
[:language "en-US"]
;; Generate an item for each post
(for [{:keys [title slug pubDate] :as blog-metadata} (take 20 blog-info)]
(let [link (str "https://www.ryanellingson.dev/blogs/" (str/replace title #" " "-"))]
[:item
[:title title]
[:link link]
[:description slug]
[:pubDate pubDate]
[:author "Ryan Ellingson"]
[:guid {:isPermaLink "true"} (str "https://www.ryanellingson.dev" link)]
[:content:encoded (raw-string (str "<![CDATA[" (h/html (blog-page blog-metadata)) "]]>"))]]))]])))
Thankfully, Hiccup can also be used to create a pretty good RSS feed and I can use the same parser functions I've already created to populate it with the actual blog content. A few things might be wrong here and there, but it seems to be mostly consistent with the web browser version.
A Word On Styling
If it's not clearly apparent, I didn't use a provided style sheet from Tail Wind or like services, rather I just rolled my own. The tradeoff of a few people balking at my aesthetic choices is well-worth having something that looks a little unique.
Here were my general design principles:
Blue and Orange is a great color combination
Most things can be done with just HTML and CSS
Steve Jobs was right about rounded corners
I want my turtle sculpture watermarked on the right
Thoughts About Clojure
It's been awhile since I've used the parasitic language outside production and I forgot how much Clojure makes you think. If I'm writing Python code, I'm usually working in a straight line and write everything from top to bottom, 20% of the time spent thinking, 80% of the time spent writing, but with Clojure, I spend about 80% of my time thinking about what I'm writing and 20% of my time writing it.
To some extent, this is due to my inexperience with the language, however what most causes me to pause is that the structure of the program is far more clear and it's easier to tease parts of the program out to mess around with. The structural nature of a Lisp begs to be messed with and refined and sometimes this lets you make much simpler code, especially with recursive and concurrency scenarios, and other times gets you stuck in a trap of diminishing returns.
Where Clojure absolutely dominates though is with syntax. Here's Hiccup:
[:div {:class "fancy-div"} [:h1 "my heading"] [:p "hello"] [:footer "goodbye"]]
And here's the equivalent expression in a similar python library known as dominate[10] :
with div(class_="fancy-div") as dom_element:
h1("my heading")
p("hello")
footer("goodbye")
It's a lot easier to understand what the Hiccup expression above implies and you don't have to resort to implicit behaviors implied by with. Python does get a bad rap for having more pot holes then the Shell script is was based on, but it's worth noting that Clojure is primarily a Java replacement that has also become a JS replacement, a Bash replacement, and soon maybe even a C++ replacement so there's a larger phenomenon of people preferring lisp over procedural patterns when they can get it.
Pragmatically, I think it's still important to know "easier" languages like Python since they're many instances where you end up working with folks from Ops who're writing CI/CD automation, data scientists who are writing reports and PySpark pipelines, and Python just gets things done fast if you have a little experience with it. API glue servers, k8s operators, and ad-hoc ingestion scripts can all be rolled quickly, maybe they're not fast or especially durable, but at the point you need those things it's pretty simple to do a Golang re-write.
Making Your Life Easier with Docker(Maybe)
While developing, and definitely before I sync to a web server, I like to do a quick spot-check in an environment as analogous as I can manage to deployment. For that, I use Docker to spin up an Nginx container locally, mounting the server configuration and site content to the right locations, and make the site available on port 80(localhost for most):
docker run --name static-site\
-p 80:80\
-d -v "$(pwd)/target:/var/www/html:ro"\
-v "$(pwd)/default.conf:/etc/nginx/conf.d/default.conf:ro"\
nginx
This'll save a lot headache versus navigating through the filesystem of /target with your web browser and wondering why something works locally, but not on the server.
Future Work
The astute reader will probably point out that this parser isn't complete and is missing elements like numbered lists, tables, doesn't account for nested formatting, and lacks some elements like heading-specific properties and tags. I'm saving some of that work for later when I truly need it, possibly the subject of future posts.
As for features, there's a few things I have on the list
"Click to copy" heading links
Hovering footnotes to see their text
Image attributes, such as making them "inline" or customizing max size
Tags and a search bar for blogs
Other page types aside from blogs, such as a book recomendation list
Footnotes
ryanellingson.com was unfortunately taken, so I grabbed .dev instead, which has the unique property of enforcing SSL by default. Other options were .net or .org, which are so passee, .it.com which feels like an odd concession, and .wiki if I really wanted to lean into the "generated from a personal wiki" angle.[:pre] element and adding {:class lang} is for the benefit of Highlight JS which provides code highlighting.